Kmesh Documentation
record of kmesh project
网络
关于Linux内核网络协议栈可以参考 计算机网络基础 — Linux 内核网络协议栈。
Network Namespace
在我的理解中,每一个network namespace 都需要一个网卡,所以之前在docker的实现中,为容器设置namespace的时候都配置了一个虚拟网卡。而且根据kmesh的代码,似乎内核在处理network namespace的时候,也就是进出network namespace的时候,在虚拟网卡上会触发和物理网卡一样的系统调用。
Netfilter
参考:你知道吗?Linux中的iptables到底是什么?netfilter又是什么? 白话iptables工作原理 |097
核心:五链四表。
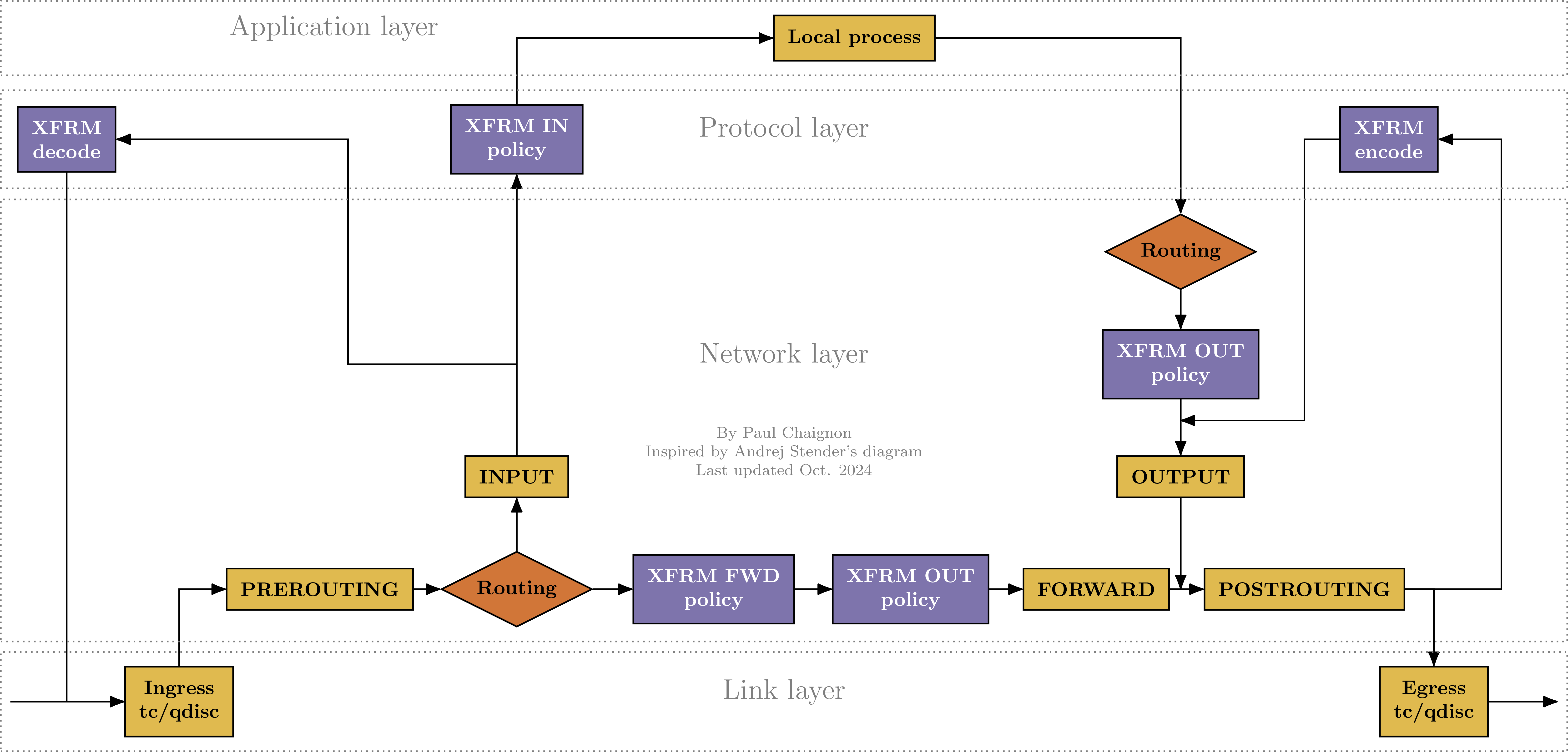
五链: Linux Netfilter中的 prerouting, input, forward, output, 和 postrouting 链。作用在网络层和传输层。
四表: filter, nat, mangle, 和 raw 表。每个表包含多个链。
五链
PREROUTING
- 作用层级: 网络层 (Layer 3) 和 传输层 (Layer 4)。
- 触发时机: 当一个数据包从任何网络接口进入系统时,在内核进行路由决策(即判断数据包是发往本机还是需要转发)之前,会立即经过此链。
- 主要用途: 目标网络地址转换 (DNAT): 这是PREROUTING最常见的用途。例如,将访问防火墙公网IP:80的数据包,修改其目标地址为内网某台Web服务器的IP:8080。这个修改IP地址的操作是典型的Layer 3行为,而修改端口号是Layer 4行为。 原始包过滤: 在路由前对数据包进行标记或过滤。
INPUT
- 作用层级: 网络层 (Layer 3) 和 传输层 (Layer 4)。
- 触发时机: 在经过PREROUTING链和路由决策后,如果内核确认该数据包的目标是本机(即发往本机上运行的某个应用程序),数据包就会进入INPUT链。
- 主要用途: 保护本机服务: 这是最核心的防火墙功能。控制哪些外部IP地址可以访问本机的哪些端口。例如,只允许特定IP访问SSH的22端口。这同时利用了Layer 3(源IP)和Layer 4(目标端口)的信息。
FORWARD
- 作用层级: 网络层 (Layer 3) 和 传输层 (Layer 4)。
- 触发时机: 在经过PREROUTING链和路由决策后,如果内核确认该数据包的目标不是本机,而是需要经由本机转发到另一个网络接口,数据包就会进入FORWARD链。
- 主要用途: 实现路由转发过滤: 当Linux主机作为路由器或网关时,FORWARD链用于过滤流经它的数据包。例如,控制内网用户可以访问外网的哪些服务,或者阻止某些外部流量进入内网。这同样是基于Layer 3(源/目标IP)和Layer 4(端口、协议)的策略。
OUTPUT
- 作用层级: 网络层 (Layer 3) 和 传输层 (Layer 4)。
- 触发时机: 当本机上运行的任何应用程序生成一个数据包并向外发送时,该数据包在进行路由决策之前会经过OUTPUT链。
- 主要用途: 控制本机对外访问: 限制本机应用程序向外发起连接。例如,禁止服务器主动连接外部的某个恶意IP地址,或者只允许root用户访问外网。 本地流量重定向: 可以对本地产生的流量进行DNAT,虽然这种用法不常见。
POSTROUTING
- 作用层级: 网络层 (Layer 3) 和 传输层 (Layer 4)。
- 触发时机: 当任何一个准备离开本机的数据包(无论是本机产生的还是转发的)在即将被发送到网络接口之前,会经过此链。这是数据包离开内核前的最后一站。
- 主要用途: 源网络地址转换 (SNAT/MASQUERADE): 这是POSTROUTING最核心的用途。例如,将所有来自内网的数据包的源IP地址,修改为防火墙的公网IP地址,从而实现内网共享上网。修改源IP地址是典型的Layer 3操作。
内核网络数据包的接收流程
IPsec
参阅 IPsec。Linux XFRM Reference Guide for IPsec。 kmesh 中的 IPsec,见项目的kmesh/docs/proposal/kmesh_support_encrypt.md文件。
IPsec 是一种网络安全协议,用于提供IP层的安全性。IPsec提供了两种安全机制认证和加密。 IPsec还需要有密钥的管理和交换功能。 IPsec的两种工作模式:
- 传输模式:只对IP数据包的有效载荷进行加密和认证,IP头部不变。
- 隧道模式:对整个IP数据包进行加密和认证,IP头部被替换为新的IP头部。根据我的理解,隧道会有一个自己的IP地址,数据包会被封装在一个新的IP数据包中,新的IP数据包的源IP地址是隧道的IP地址。
IPSec的的设置是单向的。
IPsec协议组
IPsec协议组包括:
- AH(Authentication Header):提供数据包的认证和完整性保护,但不提供加密。可以单独使用,也可以在隧道模式下,或与ESP一起使用。
- ESP(Encapsulating Security Payload):定义了加密和和可选认证的应用方法。由三部分组成:ESP头部、ESP有效载荷和ESP可选尾部。头部包含两部分:安全策略索引和序列号。ESP有效载荷是加密后的数据包内容。尾部包含填充和认证数据。
- IKE(Internet Key Exchange):主要是对密钥交换进行管理,主要包括三个功能:
- 密钥协商:对使用的协议、就爱密算法和密钥进行协商
- 密钥交换:方便的密钥交换机制
- 跟踪: 对以上的这些约定进行跟踪。
IPsec的工作模式
IPsec的工作模式有两种:传输模式和隧道模式。
- 传输模式:只对IP数据包的有效载荷进行加密和认证,IP头部不变。
- 隧道模式:对整个IP数据包进行加密和认证,IP头部被替换为新的IP头部。
IPSec 的数据包传输流程
ipsec的传输流程可以参考Linux XFRM Reference Guide for IPsec中的图片如下
使用隧道模式的时候,新的ip头部的ip是什么? 新的IP头部的IP地址是如何确定是根据IPsec的Policy来确定的。Policy中会指定源IP和目标IP。 样例如下,假设容器的地址为10.xx, 节点ip为192.xx,那么使用的就是容器虚拟网卡地址,如果tmpl后指定的是节点的ip地址,那么就是节点的IP地址。
ip xfrm policy add src 10.244.1.10 dst 10.244.2.10 \
dir out tmpl src 10.244.1.10 dst 10.244.2.10 \
proto esp mode tunnel
ip xfrm policy add src 10.244.1.10 dst 10.244.2.10 \
dir out tmpl src 192.168.1.10 dst 192.168.1.20 \
proto esp mode tunnel
数据包解密的过程不依赖于Policy,首先是找到对应的State进行解密。
Tc 流量控制
关于Linux tc流量控制参考 Linux tc流量控制。
Queueing Discipline
Linux 内核中用于管理网络流量的核心机制。它控制数据包在网络接口上的排队、调度和发送行为。
网络接口 (eth0)
│
├── Root Qdisc (根队列规则)
│ ├── Class 1 (流量类别1)
│ │ └── Leaf Qdisc (叶子队列规则)
│ └── Class 2 (流量类别2)
│ └── Leaf Qdisc
└── Ingress Qdisc (入站队列规则)
eBPF
eBPF程序被加载到内核之后,内核会为其分配一个唯一的文件描述符,本质上是一个指向内核中eBPF程序对象的引用。
如何动态加载eBPF程序
BPF_PROG_LOAD 系统调用可以用来加载eBPF程序。这个调用会将eBPF程序加载到内核中,并返回一个文件描述符(FD)。
虚拟网络下的数据包路由机制 (Claude Sonnet生成)
节点内Pod间通信的网络拓扑
在Kubernetes等容器编排系统中,节点内的网络架构通常如下:
Pod1 (ns1) Pod2 (ns2) Pod3 (ns3)
| | |
veth1 veth2 veth3
| | |
veth1-peer veth2-peer veth3-peer
| | |
└──────────────┴──────────────┘
|
br0 (网桥)
|
eth0 (物理网卡)
每个Pod都有自己的网络命名空间,通过veth对连接到主机的网桥,网桥再连接到物理网卡。
节点内通信数据包流转详解
场景:Pod1向Pod2发送数据包
- Pod1内部发送
- 应用程序调用系统调用(如sendto)生成数据包
- 数据包在Pod1的网络栈中处理,经过Pod1的路由表
- 确定下一跳为网关(通常是veth1的对端IP)
- 离开Pod1网络命名空间
- 数据包通过veth1发出Pod1的网络命名空间
- 在veth1上可能触发TC egress钩子(如Kmesh的tc_mark_encrypt程序)
- 数据包到达主机网络命名空间的veth1-peer
- 主机网络命名空间处理
- 数据包在veth1-peer上触发ingress处理
- 经过主机的netfilter PREROUTING链
- 进行路由查找,发现目标Pod2的IP对应br0网桥
- 关键点:数据包不会经过物理网卡eth0
- 网桥转发
- br0网桥查找MAC地址表,找到Pod2对应的veth2-peer端口
- 数据包直接从veth1-peer转发到veth2-peer
- 这个过程完全在内核的二层转发中完成
- 进入Pod2网络命名空间
- 数据包从veth2-peer进入veth2
- 在veth2上可能触发TC ingress钩子
- 数据包进入Pod2的网络命名空间,经过Pod2的netfilter INPUT链
- 最终到达Pod2的应用程序
关键技术原理解析
1. 为什么节点内通信不经过物理网卡?
- 路由决策:内核路由表明确指示目标IP通过br0网桥可达,无需经过eth0
- 二层转发:网桥工作在数据链路层,直接进行MAC地址转发
- 内核优化:Linux内核对同一主机内的虚拟网络进行了优化,避免不必要的物理网卡处理
2. veth对的工作原理
// 内核中veth的核心实现概念
struct veth_priv {
struct net_device *peer; // 指向对端设备
atomic64_t dropped;
};
// 当数据包从一端发送时,直接转发到对端
static netdev_tx_t veth_xmit(struct sk_buff *skb, struct net_device *dev)
{
struct veth_priv *priv = netdev_priv(dev);
struct net_device *rcv = priv->peer;
// 直接将数据包发送到对端设备
if (likely(veth_forward_skb(rcv, skb, false) == NET_RX_SUCCESS)) {
// 统计更新
}
return NETDEV_TX_OK;
}
3. Linux网桥的转发逻辑
// 网桥转发决策的核心逻辑
int br_handle_frame_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_bridge_port *p = br_port_get_rcu(skb->dev);
struct net_bridge *br = p->br;
struct net_bridge_fdb_entry *dst;
// 查找目标MAC地址
dst = br_fdb_find_rcu(br, eth_hdr(skb)->h_dest, vid);
if (dst) {
// 找到目标端口,直接转发
br_forward(dst->dst, skb, false, true);
} else {
// 未找到则广播
br_flood(br, skb, BR_PKT_UNICAST, false, true);
}
}
与跨节点通信的对比
节点内通信路径:
Pod1 → veth1 → veth1-peer → br0 → veth2-peer → veth2 → Pod2
跨节点通信路径:
Pod1 → veth1 → veth1-peer → br0 → eth0 → 物理网络 → 目标节点eth0 → 目标节点br0 → 目标veth-peer → 目标veth → 目标Pod
虚拟网络性能特征
1. 内核态处理
- 所有的veth、网桥操作都在内核态完成
- 避免了用户态/内核态切换的开销
- 数据零拷贝在某些场景下成为可能
2. CPU缓存友好
- 节点内通信数据包在同一CPU核心的缓存中处理
- 避免了网卡DMA和中断处理的开销
3. 延迟特征
- 节点内通信延迟通常在微秒级别
- 跨节点通信需要经过物理网络,延迟通常在毫秒级别
Kmesh中的IPsec加密范围再解析
基于以上虚拟网络原理,我们可以更深入理解Kmesh的IPsec设计:
1. 为什么节点内不需要加密?
- 数据包完全在可信的内核环境中流转
- 没有经过不可信的物理网络传输
- 节点内的所有虚拟网络组件都在同一安全域内
2. 跨节点加密的必要性
- 数据包必须经过物理网卡和外部网络
- 物理网络可能被窃听或篡改
- IPsec在eth0上进行加密/解密,保护数据包在物理网络中的传输
3. Kmesh的KNIMap设计合理性
// KNIMap只包含跨节点的Pod CIDR
// 节点内的Pod IP不会出现在KNIMap中
// 因此tc_mark_encrypt程序不会对节点内流量进行标记
if (bpf_map_lookup_elem(&kni_map, &key)) {
// 只有跨节点的目标IP才会被标记为需要加密
mark_encrypt(ctx);
}
这种设计既保证了跨节点通信的安全性,又避免了节点内通信的不必要加密开销。
其他
什么是Boot ID? Boot ID 是Linux系统中的一个唯一标识符,用于标识系统的每次启动。每当系统重新启动时,内核会生成一个新的、全局唯一的Boot ID。
cat /proc/sys/kernel/random/boot_id
# 输出示例:7b271d9b-6642-4ca7-bb9f-2649b28a90cf
Boot ID的特征
- 唯一性:每次系统启动都会生成一个全新的Boot ID
- 格式:通常是一个128位的UUID(通用唯一标识符),格式类似:550e8400-e29b-41d4-a716-446655440000
- 长度:标准格式包含连字符共36个字符
- 持久性:在单次启动期间保持不变,重启后更新
struct sock (Socket) 代表: 网络连接或套接字 作用: 管理连接状态、缓冲区、协议信息 位置: 内核网络栈的核心数据结构 struct sk_buff (Socket Buffer) 代表: 网络数据包 作用: 承载网络数据在协议栈间的传递 位置: 网络数据包的核心载体